
如何在Precision工作站上运行量化AI模型
生成式人工智能(GenAI)彻底改变了计算世界,戴尔科技的用户都开始考虑借助大语言模型(LLM)去开发能够提升其公司生产力、效率和创新力的新功能。戴尔科技拥有全球最丰富的AI基础设施产品组合,从云到客户端设备一应俱全,因此能够为用户提供满足其一切AI需求的端到端AI解决方案和服务。戴尔科技还提供专为助力AI工作负载而设计的硬件解决方案,包括工作站、高性能计算服务器、数据存储、云原生软件定义基础设施、网络交换机、数据保护、HCI和各种服务。但用户所面临的最大问题之一是:如何确定一台PC能够与特定的LLM有效配合。戴尔科技将尝试解答这个问题。
首先应该掌握一些关于如何帮助PC处理LLM的基础知识。虽然AI例程可以在CPU或被称为NPU的新型专用AI回路中进行处理,但目前的主流仍然是在PC中使用NVIDIA RTX GPU进行AI处理,该GPU带有被称为“张量核心”(Tensor Core)的专用回路。RTX张量核心专门用于实现混合精度数学计算,而这是AI处理的核心。但进行数学运算只是需要考虑的因素之一,鉴于LLM潜在的内存占用量,还需要额外考虑可用的内存空间。要在GPU中最大程度地发挥AI性能,就必须将LLM处理加入到GPU VRAM。NVIDIA的GPU产品线在各种移动和固定工作站产品中都可以扩展,用户可以通过所提供的张量核心数量和GPU VRAM选项来轻松调整系统规模。请注意,某些固定工作站可以搭载多颗GPU来进一步扩大容量。
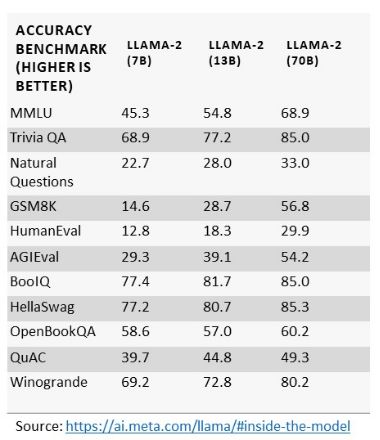
市场上出现的LLM数量和种类越来越多,但在确定硬件需求时,最需要考虑的因素之一是所选LLM的参数规模。以Meta AI的Llama-2 LLM为例,该模型有70亿、130亿和700亿这三种不同的参数规模。一般来说,参数规模越大,LLM的准确性就越高,在一般知识应用中的适用性也就越强。
无论用户的目标是将基础模型原封不动地用于推理,还是根据具体的用例和数据进行调整,他们都需要了解LLM对机器的要求以及如何最好地管理模型。如果能够利用用户专有的数据开发和训练出针对特定用例的模型,那么用户的AI项目就能为其带来最大的创新和回报。在使用LLM开发新功能和应用时,参数规模最大的模型可能会对机器性能提出极高的要求,因此数据科学家们开发出了一些办法来帮助降低处理开销和管理LLM输出准确性。
量化就是其中的一种办法。该技术通过修改LLM内部参数(即权重)的数学精度来缩小LLM的规模。降低位精度会对LLM产生两方面的影响:一是减少处理所占用的空间和对内存的需求,二是影响LLM的输出准确性。量化可以看作是JPEG图像压缩,虽然压缩得越多,创建出的图像效率就越高,但在某些用例中可能会使图像变得模糊不清。
在实际应用中,如果用户想要运行量化为4位精度的Llama-2模型,可以考虑戴尔Precision 3000和5000系列的多款移动工作站。
戴尔科技全新的3000和5000系列移动工作站集成了CPU,NPU,GPU多处理器组合,能够优化100多款应用中的AI性能,使其运行更快、能效更高。例如,它们可支持全新的协作体验,如AI驱动的视频会议,提供背景模糊、面部取景和视线纠正等功能。NPU能有效地卸载CPU或GPU上的任务,使功耗降低高达40% 。这意味着电池续航时间更长,用户无需频繁充电即可持续工作。此外,新款CPU还配备了速度更快的集成显卡,为更多媒体密集型AI工作负载提供卓越性能。CPU、NPU和GPU协同工作,共同打造灵活、高性能且节能的AI引擎,为用户带来绝佳体验。
此外,全新戴尔Precision 3490和3590移动工作站最高可搭载NVIDIA RTX™ 500 Ada图形处理器,提升专业用户的工作效率。Precision 3591则专注于设计与创作领域,轻松应对入门级2D和3D CAD应用。而Precision 5000系列移动工作站将创意应用的性能提升到了新的高度,Precision 5690凭借其小巧的16英寸机身 ,为用户带来出色的创意应用体验。它具备广阔的视野、出色的便携性和强大的应用性能,最高可配备NVIDIA RTX™ 5000图形处理器。同时,机身小巧但强大功能的Precision 5490作为一款14英寸超便携设备,在性能和体验方面也毫不逊色。
在更高精度(BF16)运行会增加对内存的需求,但戴尔科技的解决方案可以在任何精度上满足任何规模的LLM需求。戴尔Precision 7960 塔式工作站可支持多达四个NVIDIA 高性能GPU,其AI处理能力比上代产品高出80% 且每个GPU的VRAM高达48GB,而VRAM是处理GenAI大语言模型最关键的配置之一。
那么如何解决输出准确性所受到的影响?另一种被称为微调的技术可以通过在特定数据上重新训练LLM的参数子集来提高准确性,进而提高特定用例中的输出准确性。微调会调整某些已训练参数的权重,能够加快训练过程并提高输出准确性。通过将微调与量化相结合,就可以产生针对特定应用的小语言模型,这些模型非常适合部署到对AI处理能力要求较低的各种设备上。同样,如果开发人员想要对LLM进行微调,也可以放心地将Precision工作站作为构建GenAI解决方案过程中的沙盒。
在使用LLM时这些不同技术不会相互排斥。把它们结合在一起使用往往会带来更高的运行效率和准确性。
总之,LLM的规模以及哪些技术能够为有效使用LLM所需的计算系统配置提供最佳参考都是关键的决定因素。戴尔科技坚信无论用户在其AI旅程中想要朝哪个方向发展,戴尔科技的台式机、数据中心等解决方案都将为其提供助力。
本文由方向对了资讯网发布,不代表方向对了资讯网立场,转载联系作者并注明出处:https://zhenyes.com/industry/2319.html
