
小鹏集团发布X-Mind:让自动驾驶拥有“预见未来”的大脑
在今年6月美国丹佛举办的CVPR 2026具身智能基座模型部署研讨会中,小鹏集团通用智能中心负责人刘先明首次披露世界模型完整的技术图谱,他提出,主动思考、可控生成和长时序推演是优秀的世界模型必须具备的三大能力,也是世界模型能在自动驾驶领域应用的前提条件。
今年上半年,小鹏研发团队陆续发表了X-World、X-Foresight、X-Cache一系列学术报告,围绕可控生成、长时序推演拆解研究方法。近日,面对让模型主动思考、拉高预见能力上限的难题,小鹏集团正式发布X-Mind技术框架,通过内嵌预测性世界模型,赋予车载智能体高效的视觉思维链,攻克了认知推理与实时计算之间的矛盾,为实现真正安全、拟人的自动驾驶提供了全新的技术范式。
告别直觉驾驶,学会“前瞻推理”
传统的行业内主流方案停留在“感知即行动”的反应式映射阶段,这就好比一个驾驶员只盯着眼前的瞬间画面踩电门,缺乏对物理世界时空演化的显式预测能力。
具体而言,显性的不足之处有:首先,基于文本的思考难以精准表达复杂的环境几何信息;其次,基于未来图像的预测又包含大量、高频冗余的纹理数据,反而缺少了对自动驾驶任务十分重要的深度语义信息。
基于此,小鹏的研发团队提出创新性的思考,让模型在输出动作之前,先进行一场高效的脑内推演:将视觉思维链(Visual CoT)实例化,在动作生成之前执行显式的时空推演。这意味着车辆可以像经验丰富的老司机一样在驾驶的时候可以想在前头,让每一条规划出来的路径都考虑到未来交通流的变化,具备更好的防御性驾驶能力。X-Mind正是用来解决认知推理与实施部署之间矛盾的利器,赋予VLA模型前瞻性的物理推理能力。
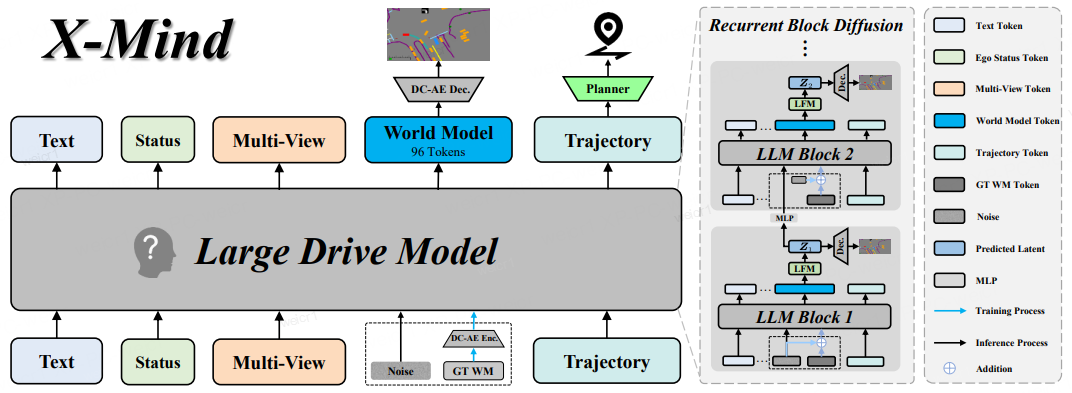
X-Mind 的整体架构如上所示。预测世界模型无缝嵌入在大型驾驶模型中。通过使用循环块扩散机制,网络在单次前向传播中,在其不同的内部层上执行渐进式去噪步骤,以生成紧凑的抽象草图。基于这种预期的物理未来推演,规划器得出最优的自车轨迹。蓝色箭头表示训练数据流,而黑色箭头展示推理过程。
X-Mind:打破黑盒,从本能反应进化为心理博弈
与X-Foresight一样,X-Mind也同样致力于将预测世界模型集成到端到端驾驶模型中,但在表现形式、技术侧重点和对车端VLA的赋能维度上有着明显的区别:X-Foresight在架构上与VLA融为一体,在统一的token空间内联合预测未来的多视角画面与自车动作,为VLA控车决策提供了核心支撑,侧重在“看”未来的画面来理解世界如何演变。X-Mind则是为VLA提供思考的画布,在车端算力有限的情况下进行高频的认知推理,并利用视觉思维链可视化的理解模型决策背后的逻辑,侧重在行动之前建立一段类人的高效思考过程。它们两者将共同驱动小鹏VLA模型向着具备物理常识、会预判、且推理透明的通用物理AI进化。
围绕“想的快、想的清楚”这一核心目标,X-Mind的原理是将反应式黑盒映射转变为预测性的显性认知推理,简单来说,就是可视化、透明化的理解模型决策背后的逻辑。
1. 思维草图 实现高效视觉思维表示
思维草图的灵感源自人类的认知心理学,X-Mind抛弃了对高清纹理的执着,转而构建了一种融合了鸟瞰图(BEV)布局与抽象驾驶先验的“认知画布”。
- 思维草图包含什么? 物理场景元素(车道线、障碍物)、动态交通灯状态、自适应导航意图以及合规车速轮廓。
- 优势是什么? 通过深度压缩自编码器(DC-AE),将12帧的未来世界推演压缩至仅96个Token。这证明了相比于高冗余的图像或昂贵的 3D 重建,思维草图能更有效地过滤掉与规划无关的纹理干扰,仅保留道路拓扑、交通灯状态和导航意图等核心语义先验,从根本上解决了长上下文带来的计算瓶颈,让“思考”变得轻量且高效。
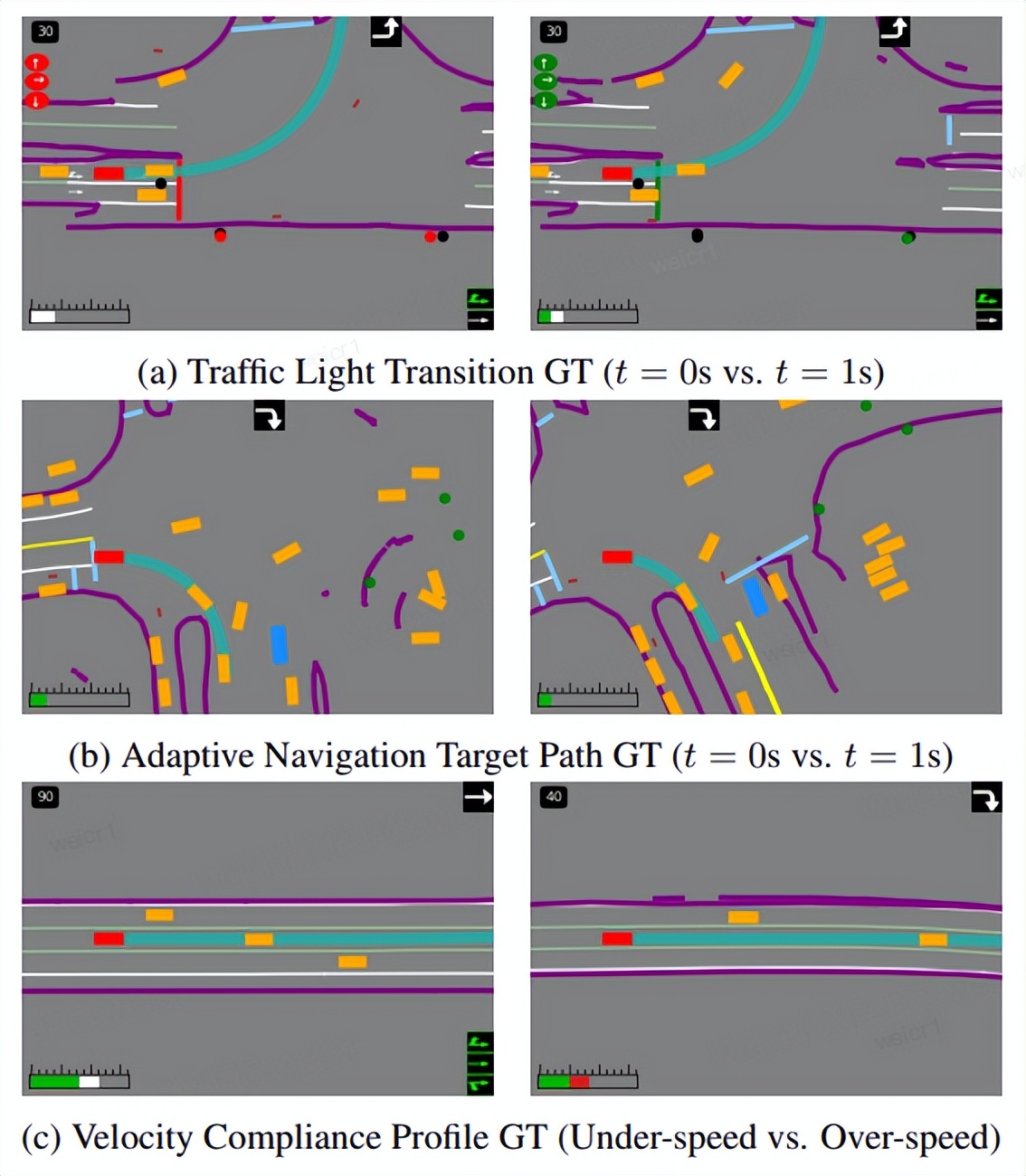
结构化思维草图的可视化
这类标注是用于训练世界模型的高保真监督信号,包含:(a) 动态交通灯状态、(b) 自适应导航意图、(c) 速度合规轮廓。密集且具备结构化特征的标注,是模型习得复杂驾驶物理规则与语义规则的关键。
2. 递归块扩散机制 生成高质量的未来推演
传统的扩散模型生成未来画面需要多次迭代,耗时严重。X-Mind创新性地设计了递归块扩散(RBD)机制,在大型驾驶模型不同的内部层中进行内化生成,实现在单次前向传播中完成高质量的未来推演。
小鹏研发团队开展了标准基线、单步去噪以及RBD机制三者之间的对比实验,实验数据显示:RBD的图像生成质量远优于单步去噪(FID: 9.59 vs 67.30),且推理延迟几乎持平,成功解决了认知推理与实时部署之间的矛盾。
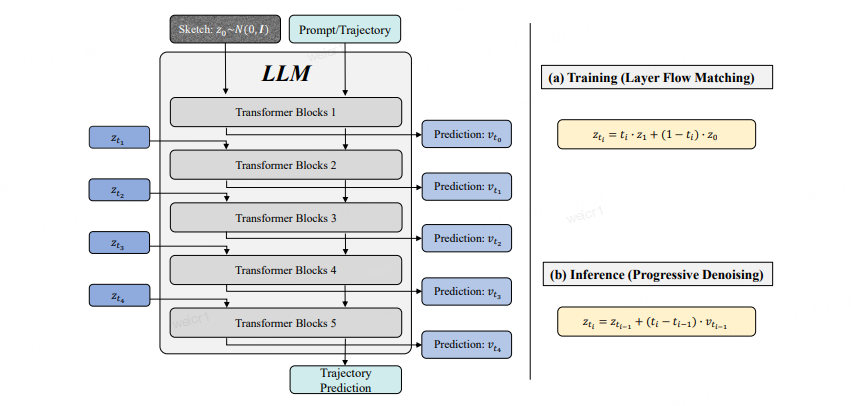
递归块扩散机制整体架构
首先将大语言模型的所有 Transformer 层划分为五个模块。训练阶段,把输入至每个模块、对应场景草图的词元特征,替换为不同强度噪声与真值数据的线性组合;随后从对应模块的输出中提取该类词元特征,并解码以预测车速。推理阶段,采用固定时间步长的欧拉积分方式,将前序模块的输出作为后续模块的输入进行计算。
3. 思维链的可视化 直观展示主动思考的过程
通过思维链(CoT)的可视化,实验直观地展示了模型在做出动作前,如何在心理画布上先推演出未来的障碍物占位和车道连通性。规划器不再是盲目拟合轨迹,而是基于逆动力学推导出最优的自车轨迹。这意味着每一条规划出的路径都符合物理规律,且充分考虑了未来交通流的变化。
这种“主动思考”的可视化方法,不仅用于验证算法性能,更是建立用户信任和软件调试的关键工具。
实战验证:攻克长尾场景,提升安全性
在包含数亿帧真实世界数据的训练集上,X-Mind已经展现了卓越的性能。无论是面对前车的急刹、匝道汇入,还是复杂的十字路口博弈,X-Mind都能提前推演出障碍物的占位和场景因果链条。对比实验数据表明:
- 精度提升: 相比传统VLA模型,X-Mind在横向和纵向的轨迹预测误差(ADE)上均有显著降低,特别是在复杂长尾场景下,安全性与合规性大幅提升。
- 效率革命: 与使用原始图像或3D高斯溅射(3DGS)作为中间表示的方案相比,X-Mind的推理延迟极低,具备了在资源受限的车规级芯片上量产落地的可行性。

未来BEV预测的定性比较。图片展示了白天和夜间场景下的未来空间推演结果。与基于单步生成的基准方法(中间行)相比,X-Mind所提出的递归块扩散(RBD) 框架(底行)产生了极为准确且时间上连贯的预测。至关重要的是,即使是在GT监督中缺少动态物体的情况下,RBD框架也展现出了预测动态物体运动的认知能力。
关键拼图:补足小鹏物理世界基座模型的技术图谱
X-Mind的发布,初步解决了车端算力约束下难以清晰表达“思考过程”的难题,它与X-World、X-Foresight共同组成小鹏物理AI基座模型的研发谱系,成功激活主动思考、可控生成和长时序推演三大核心能力,让模型不仅学习“如何行动”,也能理解“行动之后世界会如何变化”。
近年来,小鹏研发团队正在通过模型、数据与训练目标的规模化,不断提高基座模型的性能,持续探索规模法则的上限。随着第二代VLA能力的不断提升,其在环境理解、推理决策和行动执行等方面形成的能力体系,正加速向更广泛的具身智能场景延伸。小鹏集团将加速突破性技术的开发、量产应用,继续谱写物理AI驱动的未来图景。
更多信息可访问X-Mind页面:https://xp-x-mind.github.io/en/
———————————————————————————————————————————————————————————
附:小鹏物理AI基座模型相关论文
1. X-World
论文:https://arxiv.org/pdf/2603.19979
官网:https://x-world-1.github.io/
2. X-Cache
论文:https://arxiv.org/abs/2604.20289
官网:https://x-cache-1.github.io/en/
3. X-Foresight
论文:https://arxiv.org/abs/2605.24892
官网:https://x-foresight-1.github.io/en/
4. 2026CVPR:
https://mp.weixin.qq.com/s/sL9ZBMgNp462OUgItDOlLg?scene=1&click_id=9
5. 第二代VLA推送首月出行报告
第二代VLA推送首月,辅助驾驶里程占比首次突破 50%,超一半路程由AI司机完成,成为行业首个迈过这一关键节点的智能辅助驾驶系统。
https://mp.weixin.qq.com/s/ZAa87QofkoRemXt88YP-Aw
6. 刘先明的X.COM长文解析小鹏关于世界模型的系统思考
https://x.com/i/status/2062431885834473596
英文原文:
Building the World Model for Autonomous Driving
What is the role of a world model in autonomous driving, or more generally, in Physical AI?
Our answer is that a world model is not a replacement for VLA. It is another scaling path toward the same goal — a foundation model that understands the physical world well enough to act in it, which is our ultimate goal in creating VLA 2.0 to scale up the ability of autonomous driving.
Two Sides of the Same Problem Question
A VLA model learns from human actions. Given video streams and instructions, it outputs action sequences or direct control signals. The supervision is sparse, but extremely high-level: human actions implicitly encode perception, reasoning, intent, risk, social interaction, and physical understanding.
A world model learns from the world itself. Instead of only predicting actions, it can predict future states, future observations, or latent future representations. The supervision is denser: every frame, every motion, every interaction becomes a training signal.
They are two complementary objectives for training a Physical World Foundation Model, as
- VLA learns from what humans do.
- World models learn from how the world evolves.
Three Ingredients of World Models:
For driving, however, a useful world model cannot be just a passive video generator. It needs three key ingredients:
- Thinking: Before a model acts, we want to understand what it is “thinking.” For VLA systems, interpretability is essential for debugging, trust, and iteration. Our X-Mind work explores this through CoT-style visualization of intermediate reasoning behind driving decisions.
- Control: A world model for driving must be controllable. If the ego vehicle turns, accelerates, brakes, or changes lanes, the generated future must respond physically and geometrically. This is the motivation behind X-World: an action-conditioned multi-camera world model that generates futures consistent with ego motion, road geometry, static structure, and dynamic interactions.
- Rollout: Driving decisions are sequential. The consequence of an action may only become clear several seconds later. This is the core idea behind X-Foresight: using long-horizon rollout to imagine possible futures conditioned on the current scene and candidate actions.
Together, these pieces point to a new stack:
- VLA provides action-aligned intelligence.
- World models provide dense physical supervision.
- Thinking exposes intermediate reasoning.
- Control makes generation action consistent.
- Rollout connects prediction to planning.
The deeper point is scaling. Autonomous driving will not be solved by hand-designing every corner case. It will be solved by scaling models, scaling data, and scaling objectives that force the model to understand the physical world.
VLA is one objective. World modeling is another.
Next Generation of Physical AI Models:
The next generation of autonomous driving systems will be trained not only to imitate human driving, but also to predict, simulate, and reason about the world before acting.
We put together all these compoents into one unified framework, where using a unified Large Foundation Model to predict both the action list and generate rolling out video sequences (using X-World scene render), as X-Foresight:
It not only improves the generation fidelity, but also improves action prediction through all axies.
Driving by understanding. Understanding by predicting. Prediction by scaling.

本文由方向对了资讯网发布,不代表方向对了资讯网立场,转载联系作者并注明出处:https://zhenyes.com/auto/8057.html
